

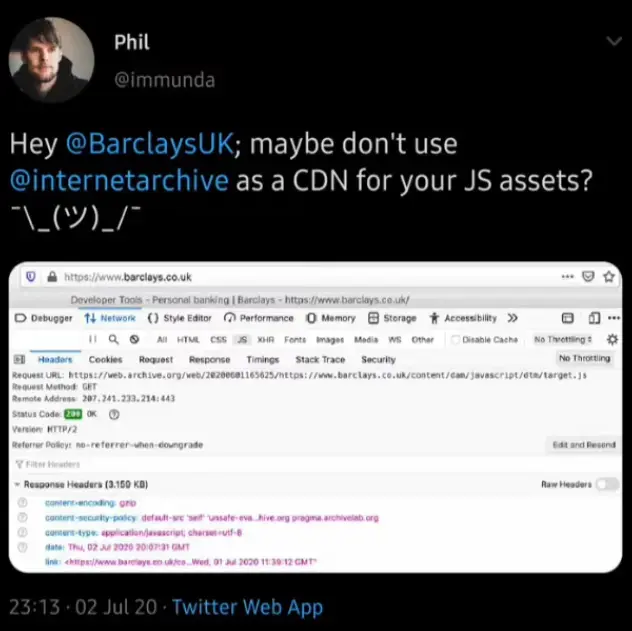
Apparently still can’t afford a server…
Removed by mod
Incompetence from a corporation that has an annual revenue of 30 billion dollars could be seen as malice.
Incopentence from the dev, malice from the company too cheap to hire actual talent
As we say in the trade, “Pay peanuts, get monkeys”.
That is disgusting
Or the contractor they hired for the site wasn’t granted the access to the assets they needed, and this hacky workaround got the job done.
It reminds me of a story that a web developer who found out that other sites were hosting his game by linking back to his website in an iframe and using it to make money off of ads. He made a check that if any calls are being made to the game from an iframe, replace the game with an image of goatse.
This is the best kind of justice
Fucking glorious!
Had to Google what is goatse… 😅
Kids today, not knowing their gaping anuses when they hear about them…
For those that don’t know
NSFW
\ \ =(🫱🌸🫲)= / /🍆\ \
I didn’t know what goatse was before, but this is so beautiful; thanks for the link!
There should be fines for doing this, it’s like opening a store inside a public library and getting surprised when people are like ‘stop mooching off a public service’
Imagine some guy working at InternetArchive replacing that file with anything else.
For example, the JS code redirecting the user to pornhub 😂
Or grabbing bank account info.
My guess is that at some point some poor web dev or web admin screwed up big time and with a heart rate nearing the colibri fluttered in panic above their laptop in attempts to restore the site, finding great relief that there was a snapshot in the archives and did not have enough presence to fix all the links to get it back online asap.
…and he didn’t think to download the files and host them properly instead? Surely this must be some kind of fallback or the user is actually browsing the internet archive, no?
They’re suggesting that they copied the HTML file, but that the archived one had modified references pointing to archive.org, which they did not notice and therefore didn’t change. So now the file fetches resources from the wrong place.
Probably the production version of JS broke something on that page, getting the infrastructure team involved in “we now need to host multiple JS versions” was scary, especially if they fucked something up, so easier to modify the code on that page to point to the archive.org snapshot of the JS
Reminds me of that period where most of Wikipedia’s traffic were for an image of a flower because some program used it as a network test
Or when Netgear just randomly picked university of Wisconsin as the NTP server for all it’s cheap routers. https://pages.cs.wisc.edu/~plonka/netgear-sntp/
Thanks for that interesting read!
Wow, really? That’s awful… Software really should come with a bill of materials to assist with inventory and audit. Obviously we’re a long way from that ideal
Why would they do such a thing? The wayback machine is not actually that fast.
It only needs to be downloaded once. I would be more worried about security since this is a bank.
I’m very curious how they got into this situation though. It seems someone copied parts of an archived page.
They archived their own page and are using Internet Archive as a relay?
It’s more likely someone inexperienced used the internet archive to recover something they deleted by accident - I assume Barkley’s uses some form of source versioning, as banks are usually a mess but not to the point of not storing their code properly, so we can exclude someone with any real experience. The question would then be how it got to production. Again, banks are a mess but regulations around software that handles anything related to money demand that changes to production be peer reviewed.
Barclays isn’t a small bank, either. They hire hundreds, if not thousands of software engineers. I’m shocked such a change made it into prod.
My guess is that their front-of-house website is managed by an agency. UK companies love using agencies for shit like this.
Even if someone was that ineperienced to not know how source versioning works (which I honestly can’t really imagine in a critical programming-related job), why wouldn’t they just download the JS file from the Internet archive and put it on the own website again?
deleted by creator
Probably at least as fast as a banking site.
Removed by mod
Honestly the archive should rate limit the request based on the Referer, then their website would slow down and become unusable without actually breaking anything.
I also wonder, if they’re this incompetent, could someone… Break their website?
Isn’t it appropriate to change the file to something offensive to prevent the leeching?
This was likely discovered when the file refused to load (perhaps because
archive.orgwas blocked by network admins). (Yes, the firewall provider Kernun classifies it as anonymous proxy)God I can’t imagine why anyone would every do that intentionally. What about when you need to update the file…? How do you know which version is served??
My first thought when I read post was of playing with the hinged mirrors of a medicine cabinet and forgetting which reflection is real
I don’t know what any of this means. Can I get a dumbed down explanation?
A website can be composed of a bunch of files that your browser downloads and then renders to what you see on your device.
One common type of file contains javascript code (aka js assets), which can sometimes be relatively large, like several megabytes (MB). If a website gets hit by a lot of users, those MBs add up, and can chew through the bandwidth allotted for the given website. Consuming more bandwidth can cost more money for the website operator, who pays a hosting company for the website’s resources (disk space, compute time, network bandwidth).
To help alleviate this, and to also make these downloads faster around the world, Content Distribution Networks(CDN) exist. The idea is that you upload your large files to the CDN, have your website link to the CDN for big files, and now browsers pull big files from the CDN when the website is loaded instead of the website’s host itself. However, contracting with a CDN costs money too, just maybe not as much as a web host charges for hitting bandwidth overages.
Another important component to note: archive.org is a non-profit that in part has a web crawler whose entire purpose is to periodically take a snapshot of every website on the internet. This isn’t just a screen cap of each website either, it’s a copy of all of the files that actually compose the website. This is an oversimplification, but is good enough for the concluding example that follows.
So back to the case in the OP. What the dev did, was choose not to pay for and utilize a CDN to link to, but rather used archive.org’s copy of large file(s) to link to. So when a user loads the website, all of the bandwidth hogging files are being served for free from archive.org. But it’s really not free from archive.org’s perspective, since they’re the ones ultimately paying for the bandwidth.
edit: Added the crawler bit.
deleted by creator
You download a copy of a photo I took to your computer.
I have a website that lets people see the photo, it’s a popular website
Except that photo on my website doesn’t point to a copy of that photo on one of my computers, it points to the copy on yours.
Millions of people visit my website, and each time they do, they download your copy of my photo.
Uploading that photo to millions of computers across the world fucks up your internet service. You could also switch out my photo for another one, maybe even an offensive one, but my website would still point visitors to it.
In the original post, this is what a multibillion dollar corporation, a bank, did to a not-for-profit service that keeps a historical record of the internet.
I hinted at the security implications of what happened, but explaining that would make the analogy too complex.
Lets go a little beyond merelly hinting at the security implications:
- The files being hosted by that 3rd party are Javascript, which is code that runs on the browser.
- Barclays is a bank.
So people go to the website of a bank and their browser receives code from a 3rd party with whom the bank has no contract and who have nothing in place to obbey the level of security that is required by a banking site.
This is way more “interesting” that the photo from that example of yours (which doesn’t have any executable code, only data, being fed to very mature image decoding libraries so it’s many times harder to find exploits for it than for code)
Consider the implications of getting the Barclays website to serve (from the point of view of a user) what can easilly be malware…
Fair, although explaining a potential vector for a hypothetical XSS attack and its implications to someone who doesn’t know what Javascript is sounds like information overload











{kind=link}