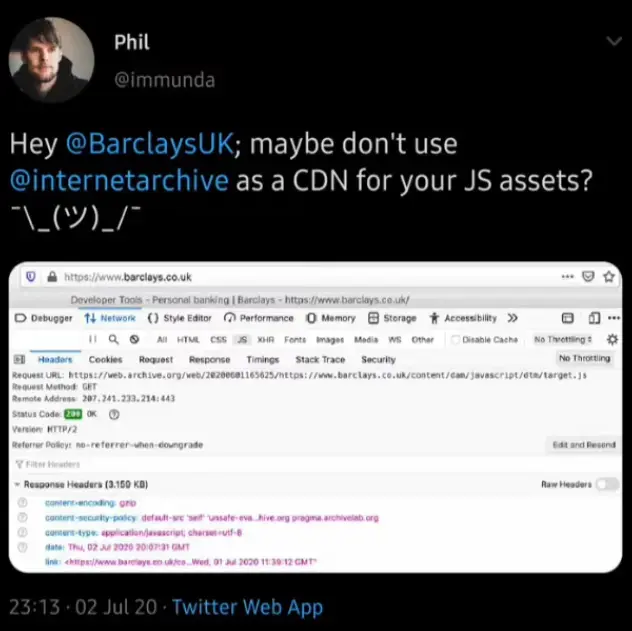
…and he didn’t think to download the files and host them properly instead? Surely this must be some kind of fallback or the user is actually browsing the internet archive, no?
They’re suggesting that they copied the HTML file, but that the archived one had modified references pointing to archive.org, which they did not notice and therefore didn’t change. So now the file fetches resources from the wrong place.
Probably the production version of JS broke something on that page, getting the infrastructure team involved in “we now need to host multiple JS versions” was scary, especially if they fucked something up, so easier to modify the code on that page to point to the archive.org snapshot of the JS

{kind=link}
…and he didn’t think to download the files and host them properly instead? Surely this must be some kind of fallback or the user is actually browsing the internet archive, no?
They’re suggesting that they copied the HTML file, but that the archived one had modified references pointing to archive.org, which they did not notice and therefore didn’t change. So now the file fetches resources from the wrong place.
Probably the production version of JS broke something on that page, getting the infrastructure team involved in “we now need to host multiple JS versions” was scary, especially if they fucked something up, so easier to modify the code on that page to point to the archive.org snapshot of the JS