NVIDIA is tanking because everyone is now looking at them and thinking “hey maybe ai doesn’t need warehouses full of graphics cards after all”. NVIDIA sells less product => their profits go down => their stock’s perceived value goes down.
Sure, but we had the same thing with Alpaca, Llama2, Llama3, 3.2, Mistral, Phi… They’re all getting smaller and/or more intelligent since a year ago (and more) when models at small size started to compete with ChatGPT, or at least claim to do so… If that’s it… Shouldn’t it have happened like a year ago? We definitely had those graphs back then, when some Llama or Mistral outperformed the current ChatGPT of the time in some benchmarks… I think precedent for that headline “… outperforms ChatGPT” or “… is better than …” is Llama2 70B in summer 2023. And claiming that has been a pretty constant thing since then.
But I think I get it. If people really thought OpenAI was going to give trillions of dollars to Nvidia for hardware, and now there is some competition and more efficient AI available… That might come as a reality check. I just think the prospect of it all is a bit funny. AI is a big bubble especially since everyone thinks it’s going to make progress and big advances… And now it does… And stock price drops… That’s just silly. IMO. And I’d bet now is a good time to buy some stocks, since the better AI gets, the more it gets applied.)
but we had the same thing with Alpaca, Llama2, Llama3, 3.2, Mistral, Phi…
I don’t believe so, or at least, them all getting smaller and/or more intelligent isn’t the point, it’s how they did it
I noted above that if DeepSeek had access to H100s they probably would have used a larger cluster to train their model, simply because that would have been the easier option; the fact they didn’t, and were bandwidth constrained, drove a lot of their decisions in terms of both model architecture and their training infrastructure. Just look at the U.S. labs: they haven’t spent much time on optimization because Nvidia has been aggressively shipping ever more capable systems that accommodate their needs. The route of least resistance has simply been to pay Nvidia. DeepSeek, however, just demonstrated that another route is available: heavy optimization can produce remarkable results on weaker hardware and with lower memory bandwidth; simply paying Nvidia more isn’t the only way to make better models.
Local AIs are making increasingly good progress but by the time they got to ChatGPT 3 quality, ChatGPT itself had already moved on to version 4 and then o1. They’re probably not going to disrupt the market until someone matches the latest ChatGPT with a 7B size model. Might happen in a year or two.


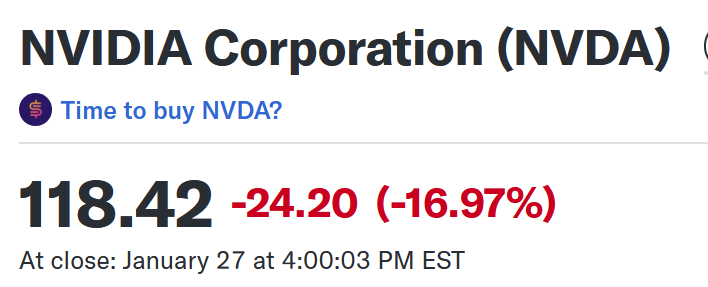
NVIDIA is tanking because everyone is now looking at them and thinking “hey maybe ai doesn’t need warehouses full of graphics cards after all”. NVIDIA sells less product => their profits go down => their stock’s perceived value goes down.
Sure, but we had the same thing with Alpaca, Llama2, Llama3, 3.2, Mistral, Phi… They’re all getting smaller and/or more intelligent since a year ago (and more) when models at small size started to compete with ChatGPT, or at least claim to do so… If that’s it… Shouldn’t it have happened like a year ago? We definitely had those graphs back then, when some Llama or Mistral outperformed the current ChatGPT of the time in some benchmarks… I think precedent for that headline “… outperforms ChatGPT” or “… is better than …” is Llama2 70B in summer 2023. And claiming that has been a pretty constant thing since then.
Edit: Computerphile covered Deepseek: https://youtu.be/gY4Z-9QlZ64
But I think I get it. If people really thought OpenAI was going to give trillions of dollars to Nvidia for hardware, and now there is some competition and more efficient AI available… That might come as a reality check. I just think the prospect of it all is a bit funny. AI is a big bubble especially since everyone thinks it’s going to make progress and big advances… And now it does… And stock price drops… That’s just silly. IMO. And I’d bet now is a good time to buy some stocks, since the better AI gets, the more it gets applied.)
I don’t believe so, or at least, them all getting smaller and/or more intelligent isn’t the point, it’s how they did it
https://stratechery.com/2025/deepseek-faq/
Local AIs are making increasingly good progress but by the time they got to ChatGPT 3 quality, ChatGPT itself had already moved on to version 4 and then o1. They’re probably not going to disrupt the market until someone matches the latest ChatGPT with a 7B size model. Might happen in a year or two.