but we had the same thing with Alpaca, Llama2, Llama3, 3.2, Mistral, Phi…
I don’t believe so, or at least, them all getting smaller and/or more intelligent isn’t the point, it’s how they did it
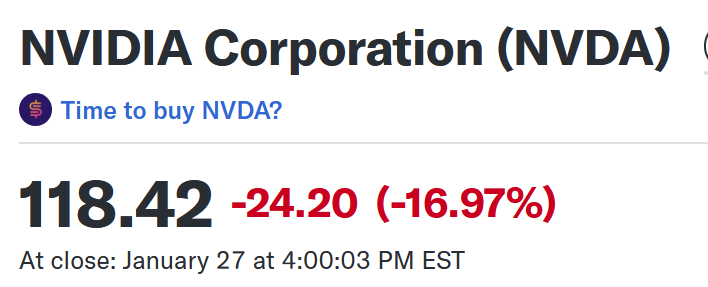
I noted above that if DeepSeek had access to H100s they probably would have used a larger cluster to train their model, simply because that would have been the easier option; the fact they didn’t, and were bandwidth constrained, drove a lot of their decisions in terms of both model architecture and their training infrastructure. Just look at the U.S. labs: they haven’t spent much time on optimization because Nvidia has been aggressively shipping ever more capable systems that accommodate their needs. The route of least resistance has simply been to pay Nvidia. DeepSeek, however, just demonstrated that another route is available: heavy optimization can produce remarkable results on weaker hardware and with lower memory bandwidth; simply paying Nvidia more isn’t the only way to make better models.


I don’t believe so, or at least, them all getting smaller and/or more intelligent isn’t the point, it’s how they did it
https://stratechery.com/2025/deepseek-faq/