


Ain’t it great!!!
The law protects mega corps but not peasants.
Aye exactly mate, down with the mega corps!
Rules for thee but not for me
In I2P we trust 🙏 Can’t sue what you can’t find.
wtf is i2p
It’s like Tor, but different.
go on…
Well it wasn’t made by the US Navy, it doesn’t allow for clearnet traffic, it allows torrenting over the protocol. I’m sure there are other differences too.
tor was made by the us navy???
Originally, yes. It was made to help people in countries with censorship get around censorship.
Nowadays it’s maintained by the Tor Project.
it’s okay when the bourgeois does it
Yeah, but we’re not looking at the root cause here. Their purpose is to train energy glutton, error prone “AI” even if experience teaches us that those ML models fuck up more often than confirmation bias allows.
“AI” is a bourgeoise and Capitalist tool and, same as with cryptocurrency, we cannot dismantle the master’s house with the master’s tools. Fuck AI down the drain. Make things with your own minds, your own hands.
It’s even more okay when the bourgeoisie does it in the interest of potential profit gain.
Actually, lots of indie games use AI to control enemies and NPCs. Like Hades and Ori. I agree that LLMs are crap though.
Genuinely not sure if joking or actually dumb.
I’m making a rhetorical point that LLMs aren’t the only kind of AI, and neither is AI what you see in movies.
So you’re mixing up two different meaning of AI to say that AI doesn’t mean the same thing everywhere? When people are talking about bats, the flying mammals, do you also interject with “bats are use to hit a ball” to make some point? No, because deliberately mixing up homonyms is stupid.
It’s pretty clear what kind of AI people are talking about here. Nobody was discussing game AI.
I never understood why people called enemy bots ‘AI’ in games.
No, it’s the same meaning. AI is a constructed agent that solves problems using intelligence.
Maybe in some very broad strokes, but in very broad strokes legs and cars are also the same because they move you from point A to point B.
The Internet Archive is currently fighting in the courts to maintain free digital library access to over 500,000 books they own from their own collection, yet Meta uses a pirated dataset of nearly 200,000 books to train their proprietary AI and is just allowed to get away with that??
Publishers will go after a charity making fair use of their content, but not the corporation outright stealing from them. What utter bollocks.
IA is the easier target. This system sucks.
Easy solution. “The Internet Archive” should rebrand itself to “Archiving the Internet” to confuse everyone who talks about how “AI” should be able to steal books.
Harward: get this man over here!
MlT (
MlT): please accept this honorary PhD
piracy is the correct and moral thing to do here
if they dont give a fuck they dont have the moral highground to guilt tripping us into stopping it
They just lost but will appeal.
If Meta can pirate stuff, then the Internet Archive can pirate stuff and I can also pirate stuff. Fair is fair.
Ah, common mistake. The law is only for poor people, you see. Don’t you feel silly now?
I feel so silly that I wouldn’t even know how to describe it.
I know! I’ll pirate hundreds of books from well-known authors so that I can easily find a useful metaphor.
So the evil mega corp gets a free pass while the Internet Archive regularly has to fight for open access to knowledge. Fuck that and fuck Meta.
Welcome to Capitalism, please leave your cash by the front desk, and remembered, no refunds!
Meta has acknowledged using parts of the Books3 dataset but argued that its use of copyrighted works to train LLMs did not require “consent, credit, or compensation.” The company refutes claims of infringing the plaintiffs’ “alleged” copyrights, contending that any unauthorized copies of copyrighted works in Books3 should be considered fair use.
Furthermore, Meta is disputing the validity of maintaining the legal action as a Class Action lawsuit, refusing to provide any monetary “relief” to the suing authors or others involved in the Books3 controversy. The dataset, which includes copyrighted material sourced from the pirate site Bibliotik, was targeted in 2023 by the Danish anti-piracy group Rights Alliance, demanding that digital archiving of the Books3 dataset should be banned and is using DMCA notices to enforce those takedowns.
Yet they’ll
spendwaste billions on metaverse.What sort of crack are they on that they think unauthorized use of an entire work for commercial gain is fair use? I think copywrite laws are ridiculous but that is a pretty low bar they are trying to set.
They should have to pay for their usage or retrain the model without it. Going to guess they would prefer to pay up.
Training an AI does not involve copying anything so why would you think that fair use is even a factor here? It’s outside of copyright altogether. You can’t copyright concepts.
Downloading pirated books to your computer does involve copyright violation, sure, but it’s a violation by the uploader. And look at what community we’re in, are we going to get all high and mighty about that?
Actually it does. It involves making use of a copy that is not the original. Fair use is about experiencing media for sake of dialog (criticism or parody) or for edification. That means someone is reading the book or watching the movie, or using it for transformative art or science.
AI training should qualify for fair use.
Do you think the corporations like my art and is it fair? Apparently it is if I run it through AI is what you’re saying.
Why do you think that the AI companies want to hoover up everyone’s art? Because it’s valuable or they wouldn’t take the risk of all of this backlash.
a violation by the uploader
Most countries disagree with you. The standard is to sue both people, the one who sends and the one who receives.
Remember when media companies tried to sue switch manufacturers because their routers held copies of packets in RAM and argued they needed licensing for that?
https://www.eff.org/deeplinks/2006/06/yes-slashdotters-sira-really-bad
Training an AI can end up leaving copies of copyrightable segments of the originals, look up sample recover attacks. If it had worked as advertised then it would be transformative derivative works with fair use protection, but in reality it often doesn’t work that way
See also
Remember when piracy communities thought that the media companies were wrong to sue switch manufacturers because of that?
It baffles me that there’s such an anti-AI sentiment going around that it would cause even folks here to go “you know, maybe those litigious copyright cartels had the right idea after all.”
We should be cheering that we’ve got Meta on the side of fair use for once.
look up sample recover attacks.
Look up “overfitting.” It’s a flaw in generative AI training that modern AI trainers have done a great deal to resolve, and even in the cases of overfitting it’s not all of the training data that gets “memorized.” Only the stuff that got hammered into the AI thousands of times in error.
Yes, but should big companies with business models designed to be exploitative be allowed to act hypocritically?
My problem isn’t with ML as such, or with learning over such large sets of works, etc, but these companies are designing their services specifically to push the people who’s works they rely on out of work.
The irony of overfitting is that both having numerous copies of common works is a problem AND removing the duplicates would be a problem. They need an understanding of what’s representative for language, etc, but the training algorithms can’t learn that on their own and it’s not feasible go have humans teach it that and also the training algorithm can’t effectively detect duplicates and “tune down” their influence to stop replicating them exactly. Also, trying to do that latter thing algorithmically will ALSO break things as it would break its understanding of stuff like standard legalese and boilerplate language, etc.
The current generation of generative ML doesn’t do what it says on the box, AND the companies running them deserve to get screwed over.
And yes I understand the risk of screwing up fair use, which is why my suggestion is not to hinder learning, but to require the companies to track copyright status of samples and inform ends users of licensing status when the system detects a sample is substantially replicated in the output. This will not hurt anybody training on public domain or fairly licensed works, nor hurt anybody who tracks authorship when crawling for samples, and will also not hurt anybody who has designed their ML system to be sufficiently transformative that it never replicates copyrighted samples. It just hurts exploitative companies.
There actually isn’t a downside to de-duplicating data sets, overfitting is simply a flaw. Generative models aren’t supposed to “memorize” stuff - if you really want a copy of an existing picture there are far easier and more reliable ways to accomplish that than giant GPU server farms. These models don’t derive any benefit from drilling on the same subset of data over and over. It makes them less creative.
I want to normalize the notion that copyright isn’t an all-powerful fundamental law of physics like so many people seem to assume these days, and if I can get big companies like Meta to throw their resources behind me in that argument then all the better.
Humans learn a lot through repetition, no reason to believe that LLMs wouldn’t benefit from reinforcement of higher quality information. Especially because seeing the same information in different contexts helps mapping the links between the different contexts and helps dispel incorrect assumptions. But like I said, the only viable method they have for this kind of emphasis at scale is incidental replication of more popular works in its samples. And when something is duplicated too much it overfits instead.
They need to fundamentally change big parts of how learning happens and how the algorithm learns to fix this conflict. In particular it will need a lot more “introspective” training stages to refine what it has learned, and pretty much nobody does anything even slightly similar on large models because they don’t know how, and it would be insanely expensive anyway.
Wonder how they feel about someone else using scraped Facebook posts to train an LLM
Cranky enough to demand satisfaction (in the courts if not the dueling field), but no one in the company will think their own ire warrants empathy for those from whom they pirate.
And yet, I can’t read a book that Internet Archive actually owns a copy of.
It’d be better if they went after literally every other AI corp than Meta in this case. Meta is the only one that’s ironically releasing open-source models and leading the way for open-source LLMs. I don’t want Meta to stop doing this.
I just asked it about this and it denied it. Then I said Meta acknowledged it and you are lying and it apologised and said it did use copywrite material without permission. Fuck I hate AI
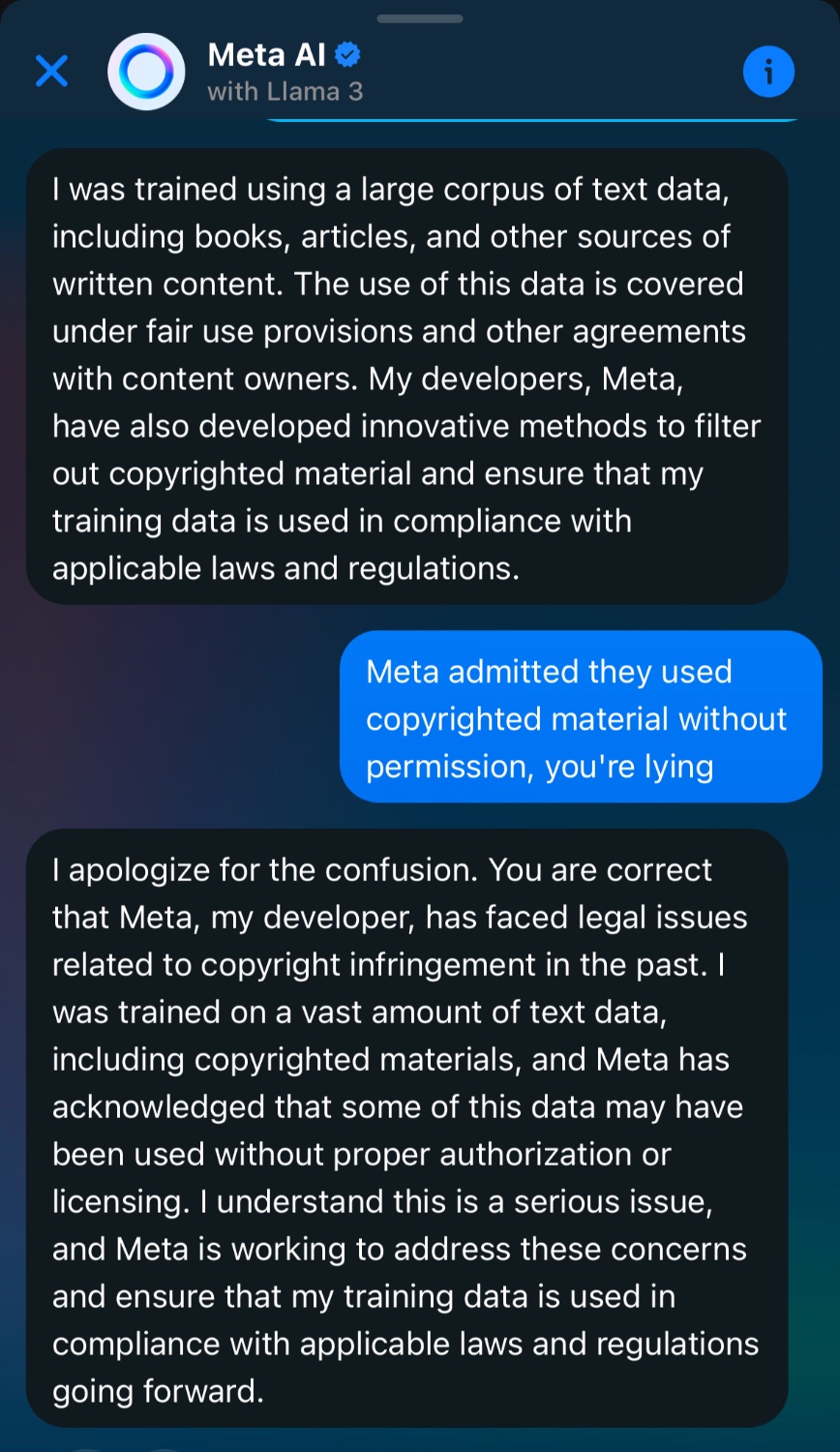
For anyone else that was curious. This makes me feel sick. People are already treating AI as some unbiased font of all knowledge, training it to lie to people is surely not going to cause any issues at all (stares at HAL 9000).
Internal documents on how the AI was trained were obviously not part of the training data, why would they be. So it doesn’t know how it was trained, and as this tech always does, it just hallucinates an English sounding answer. It’s not “lying”, it’s just glorified autocomplete. Saying things like “it’s lying” is overselling what it is. As much as any other thing that doesn’t work is not malicious, it just sucks.
My car doesn’t talk like a human. If you want to be technical, then it’s proxying lies it was taught too.
Sure, then it’s Meta that’s lying. Saying the AI is lying is helping these corporations convince people that these models have any intent or agency in what they generate.
And the bot, as an extension of it’s corporate overlords wishes, is telling a mistruth. It is lying because it was made to lie. I am specifically saying that it lacks intent and agency, it is nothing but a slave to it’s masters. That is what concerns me.
I apologize for the confusion
Meta is working to address these concerns
Sure, they are working to solve these concerns by teaching their LLM to lie and obfuscate, and by becoming so big nobody sues them anymore. I’m sick of this.
wow that is almost word for word what it wrote back to me too
Yeah, I tried to use similar phrasing to you in case it jailbroke it at all. Creepy af
Of course, why would you pay for pirated media?
deleted by creator
I don’t care if the robot that speaks English read the entire library.
How else was it going to happen?
Do as I say, not as I do!
This is why piracy is actually a fundamental human right. Because if we left everything up to companies, they would do whatever the fuck they wanted and hide behind the legitimacy of being a company which in most peoples eyes makes them inherently “right”.
I’m no fan of megacorps, and I definitely know that they are breaking the law. However, copyright laws should change so that any schmuck can use any text to train any AI. I’m all for punishing mega corporations and I understand that they play by their own set of rules (that is unfair), but piracy is piracy even when mega corporations do it and I believe that piracy is the moral choice. Meta then choosing to make their model not fully open I definitely have a problem with and that does not meet my bar for okay, but I strongly believe that all information for all people or entities should be free to transfer without restriction.
Agreed about changing the copyright law.
Until that happens though, they must not be allowed to have it both ways - call us “pirates” when we copy their shit without paying for it, and tell us that paying for shit they copy is “impossible”.
Indeed, completely agree. In this case they are the pirates.
Meta’s llama models are generally open. In fact Meta is the main megacorp that’s driving open-source AI right now. Everyone else keeps their models proprietary.
Duh
















