

Another week… another set of nerd graphs!
CPU:
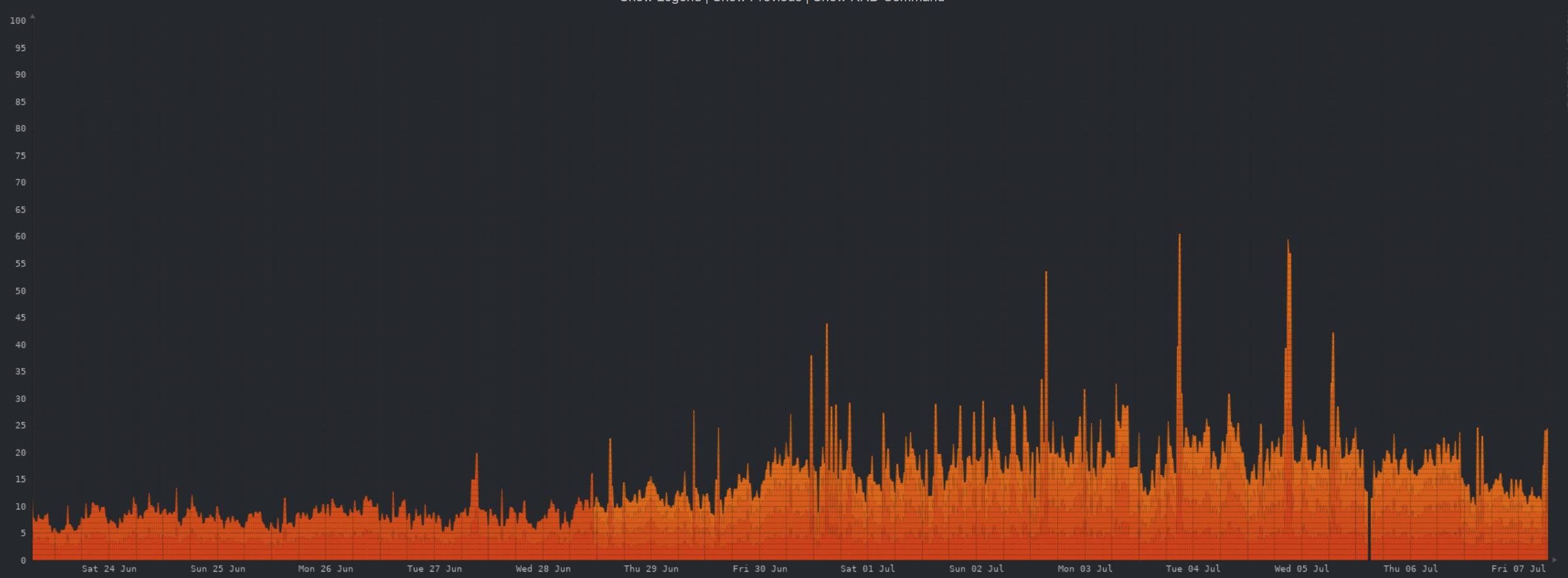
Some of the variations in CPU usage in the last week correlate with upgrades to the lemmy software. If you look closely, you can see a drop in CPU usage starting late on Thursday, this was when I upgraded to 0.18.1-rc.10 which includes some major DB query optimisations.
Memory:
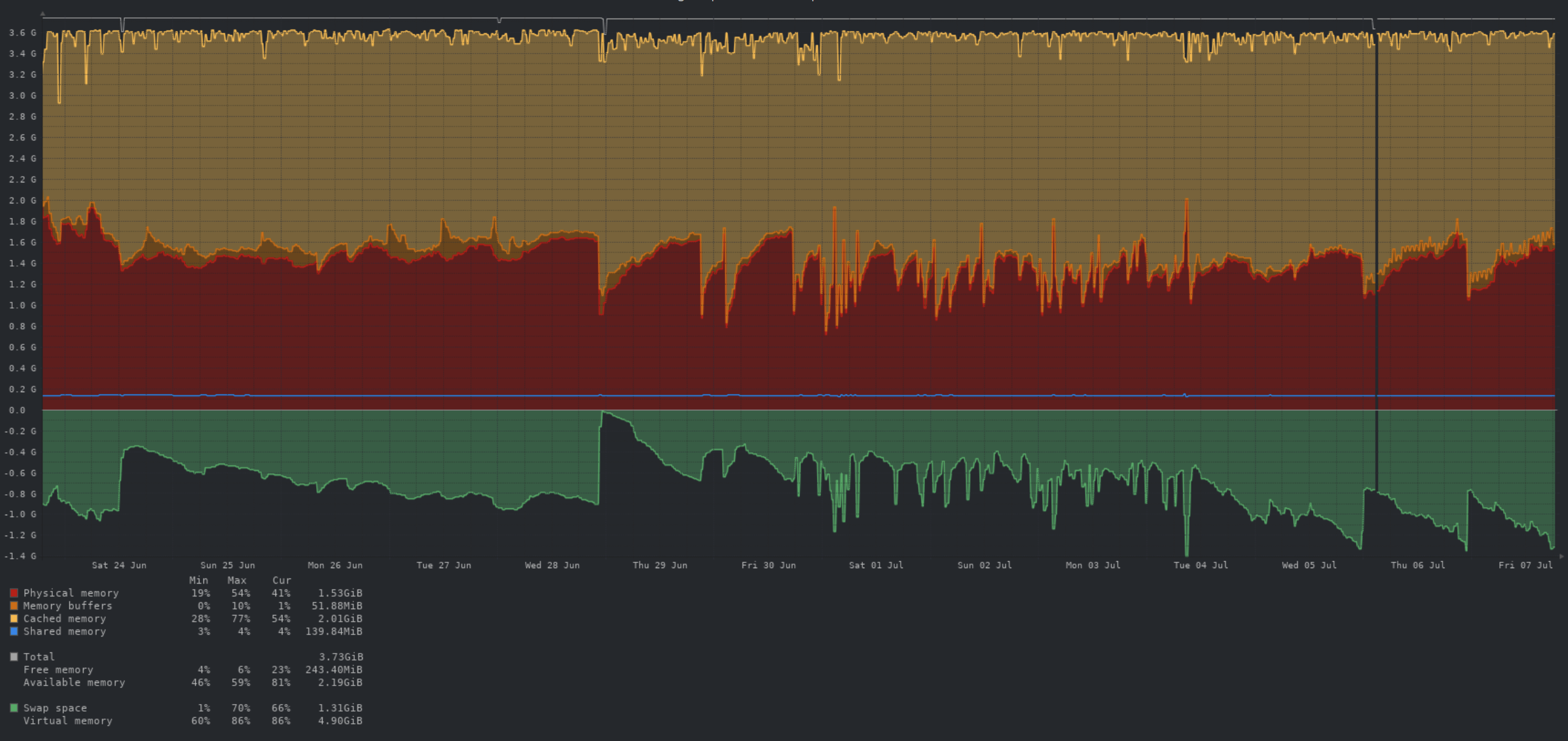
The spikey memory utilisation between the 28th of June and the 4th of July were due to a lemmy software issue. It resulted in huge resource consumption for varying amounts of time, before returning to normal. This specific issue seems to have been resolved in one of the upates this week.
Network:
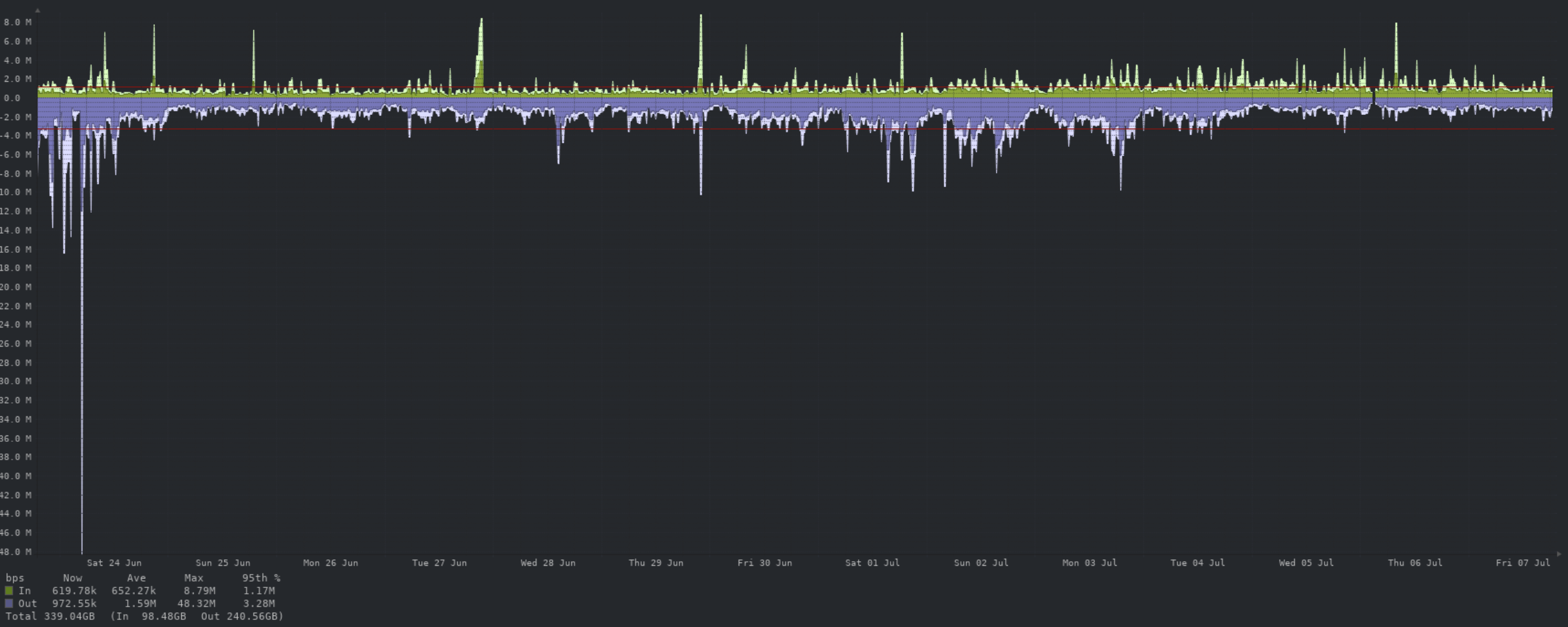
The unusually high traffic levels between the 1st and 4th were caused by a large community icon… 14MB. Thankfully, Cloudflare saved us by caching this file and saved us ~800GB of traffic on this file alone before it was shrunk to a more appropriate size 🙂
Storage:
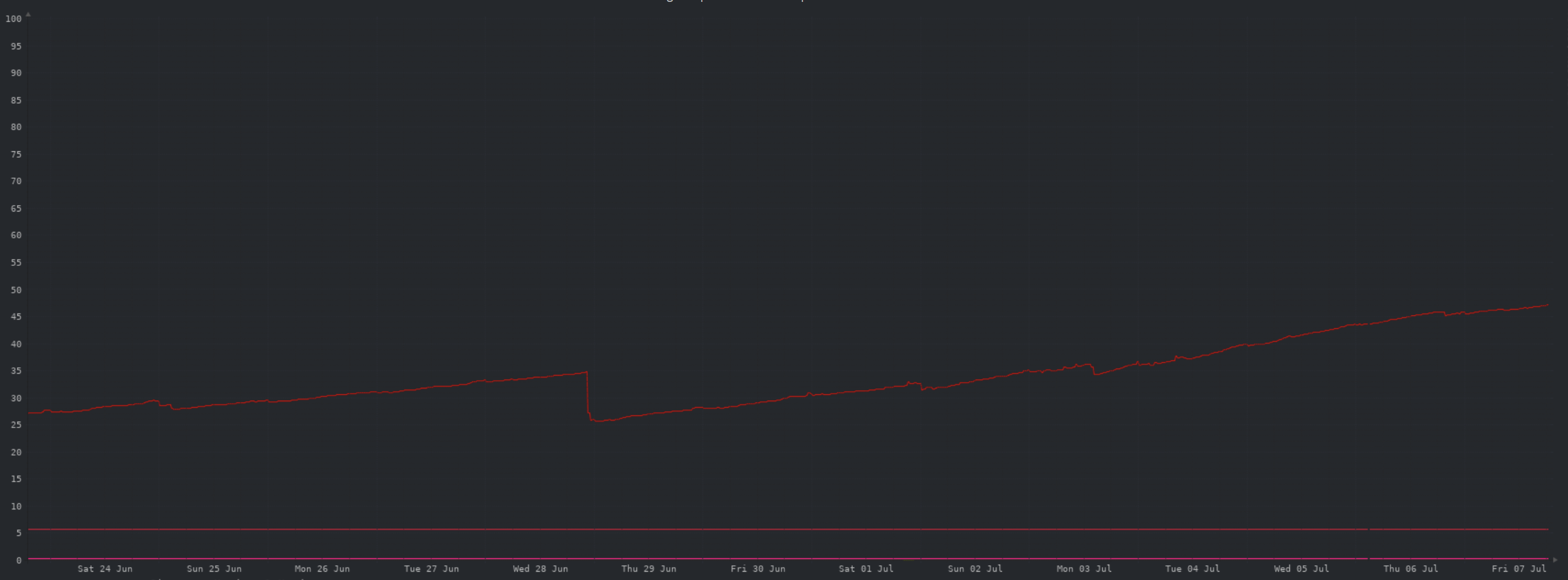
As expected, disk space is being used up at a relatively consistent rate. The drop on the 28th was when cached object storage images were deleted due to a server reboot that was required when adding 2 vCPUs. I have a scheduled job that runs every hour to delete cached objects older than a threshold. As the disk used by the cache increases (or the disk gets closer to being full), I’ll decrease the age threshold.
Cloudflare caching:
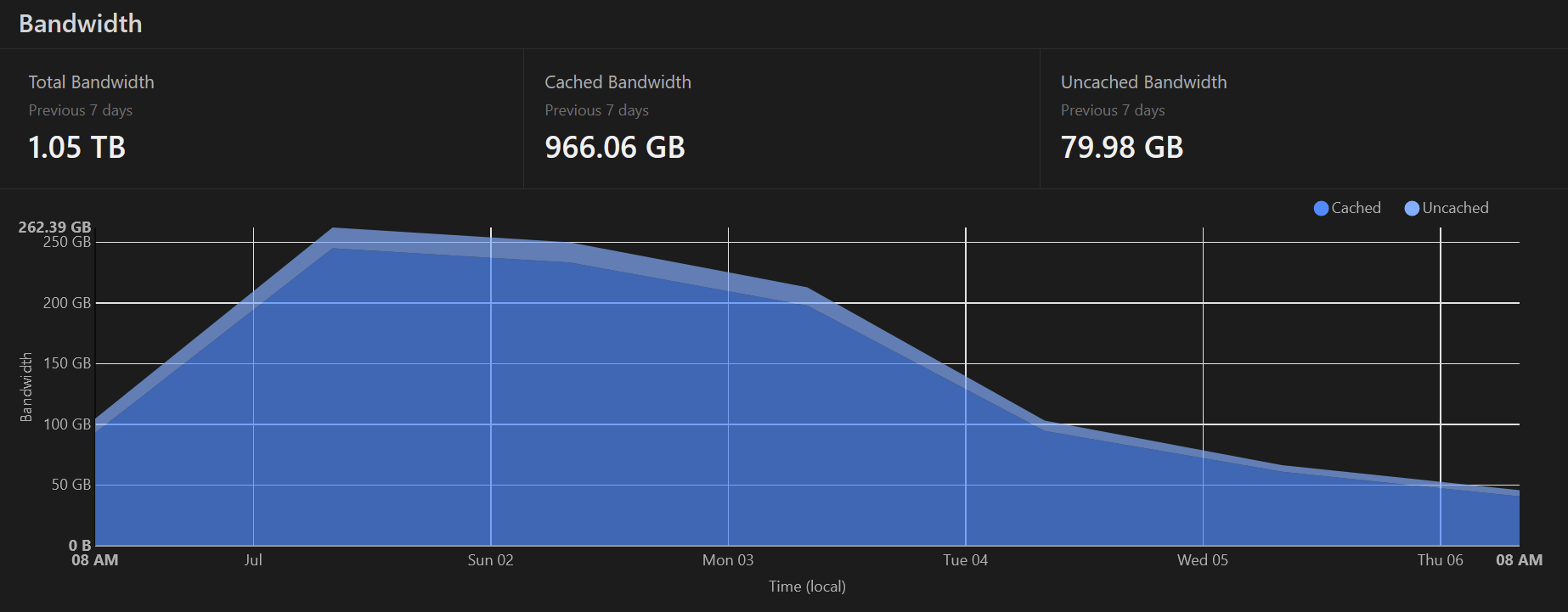
Cloudflare caching is saving us a lot of egress traffic. It is saving us less since the 14MB “icon” was shrunk, however this shows the value in the service. Even now, it is saving ~40GB of egress traffic per day.
Summary
Everything is looking pretty good right now, thanks mostly to the ongoing improvements in lemmy making things run more smoothly. In the next week or so I’ll be upgrading the storage on the VPS to cater for the ever increasing database. Admins are already discussing ways we can manage the increasing storage requirements, I’m optimistic we’ll have good solutions before we hit a VPS scaling limit.
As always, happy to answer any questions.
Interesting stuff Lodion, thanks for keeping us informed, and keeping everything running smoothly!
Very nice! I’m always impressed by the graphs and stats of larger instances and how things like storage and bandwidth are managed. Thanks for sharing, Lodion!
deleted by creator
As a nerd I appreciate this. Seems like good incremental improvement going on in the Lemmy backend side of things.
As an instance hoster, does Lemmy provide documentation around tuning and keeping your instance efficient?
does Lemmy provide documentation around tuning and keeping your instance efficient?
There are reference ansible playbooks and docker-compose files published. They include many of the settings worth looking at. But honestly the huge improvements we’ve seen recently are all down to software changes within lemmy itself, nothing to do with server configuration.
Nice, lets hope that we continue to see optimization and it doesn’t head down towards bloat from features being added.
Who was the “icon”?
It was the icon for a community here on aussie.zone
What app on the server are you using for the graphs and usage tracking?
LibreNMS with SNMP polling.
Thanks!


